Research
Coordinate transformations in the visual system
 To use vision to guide behavior, the visual system transforms the visual
inputs arriving from the retinae into different coordinate frames. These
transformations maintain a persistent representation of the visual scene during
shifts in the direction of gaze and movement of the observer. One of the goals
of the lab is to identify how these coordinate transformations are carried out
by neurons in the visual cortical hierarchy.
To use vision to guide behavior, the visual system transforms the visual
inputs arriving from the retinae into different coordinate frames. These
transformations maintain a persistent representation of the visual scene during
shifts in the direction of gaze and movement of the observer. One of the goals
of the lab is to identify how these coordinate transformations are carried out
by neurons in the visual cortical hierarchy.
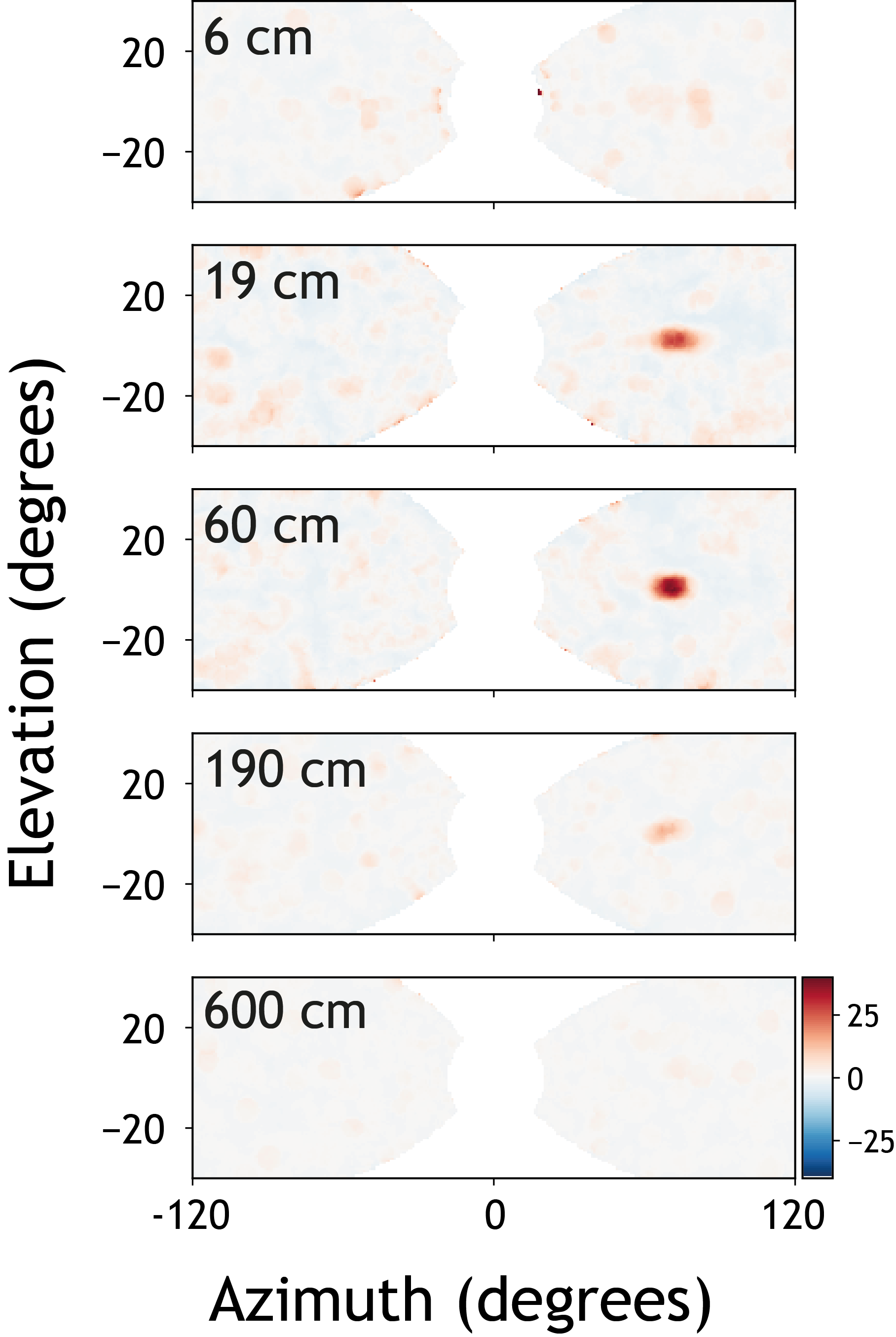
Among all the senses, vision is exceptionally attuned to provide detailed information about the three-dimensional structure of the environment. However, the visual signals available to the brain are limited to the two-dimensional images formed on the retinae and the visual system must infer the missing depth information. The ethological importance of these computations is illustrated by the fact that capacity for depth perception appears to be innate in many vertebrates and not dependent on visual experience. This suggests that evolution has imbued the visual system with hard-wired circuits for depth perception. Aiming to understand the circuit basis of these computations, we are studying how neurons in the visual cortex encode the three-dimensional location of visual cues in virtual and augmented reality environments using two-photon calcium imaging and high-density electrophysiology.
Motion parallax as a cue for depth estimation
When animals move, self-motion creates optic flow with its speed dependent on the depth of visual cues. This phenomenon, known as motion parallax, enables animals to estimate depth by comparing visual motion and self-motion speeds without relying on binocular vision. We are using in virtual reality as well as in freely moving animals to investigate how the visual system uses self-generated visual motion to estimate the depth of visual cues. A large fraction of the excitatory neurons in layer 2/3 of V1 are selective for virtual depth in virtual reality. Neurons with different depth preferences are spatially intermingled, with nearby cells often tuned to disparate depths. Many neurons respond selectively to visual stimuli presented at a specific retinotopic location and virtual depth – in other words their responses can be characterized by three-dimensional receptive fields, as shown on in the image above.